The Linux command uniq is used to remove duplicate content or find duplicated entries when processing files or data. In this post, we will explain how to use the uniq command, its options, and how to utilize it efficiently.
Table of Contents
What is the Linux Command uniq?
The uniq command is used in Linux to check for duplicate content and filter out repeated lines in files or data. However, uniq only handles consecutive duplicate lines, meaning that if duplicated content is not consecutive, it won’t provide the expected results. Therefore, it is generally common to use the sort command before using uniq to sort the file and remove duplicates afterward.
How to Use uniq
The basic syntax of the uniq command is as follows:
uniq [options] [input file] [output file][options]: Various options used to filter duplicate entries.[input file]: The file from which duplicates will be removed.[output file]: The file where the filtered results will be saved.
By default, the uniq command removes consecutive duplicate lines from the input file and saves the result in the output file. If the input file is not specified, it takes standard input (keyboard input), and if the output file is not specified, it outputs the result to the standard output (the terminal screen).
Here’s an example file:
apple
apple
raspberry
banana
banana
apple
raspberry
raspberry
watermelonWhen using the uniq command, you can see that consecutive duplicates are removed:
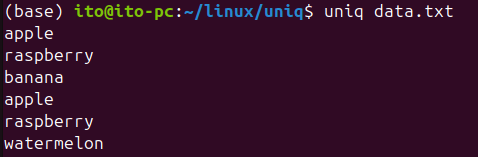
Next is an example of using the sort command along with uniq to remove duplicate lines. In this case, it gives the same result as using the -u option with sort.
sort data.txt | uniq > result.txtsort data.txt: Sorts the content of the filedata.txt.uniq: Removes consecutive duplicate lines from the sorted file.> result.txt: Saves the result into theresult.txtfile.
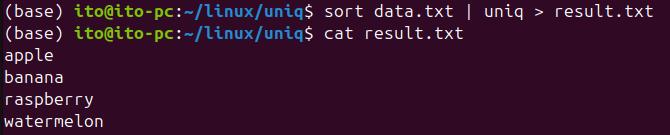
The reason for using the sort command first is that uniq only removes consecutive duplicates. If the data is not sorted, even if there are duplicate lines, uniq may not detect them.
uniq Command Options
The uniq command offers various options. Let’s take a look at some important ones.
-c (Count the number of duplicate lines)
The -c option prints how many times each line appears. This option allows you to check not only if there are duplicates but also how many times they occur.
uniq -c sorted.txtIn this example, you can see that apple appears 3 times, banana 2 times, and raspberry 3 times.

-d (Print only duplicated lines)
The -d option prints only duplicated lines. It doesn’t print unique lines, making it useful when you want to find duplicated data.
uniq -d data.txtAs shown below, only the duplicated values apple, banana, and raspberry are printed.

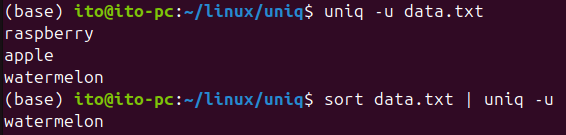
-u (Print only unique lines)
Conversely, the -u option prints only lines that are not duplicated. This option is helpful when you want to filter out unique data.
uniq -u data.txtWhen working with unsorted data, it may also show lines that are not consecutively duplicated. Therefore, remember that using uniq after sorting yields the desired result. In this case, the unique line watermelon is printed.
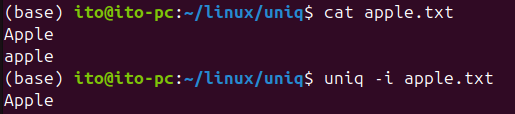
-i (Ignore case differences)
The -i option ignores case when checking for duplicates. This means that Apple and apple will be treated as the same string.
uniq -i sorted.txtAs seen in the result, Apple and apple are treated as duplicates.
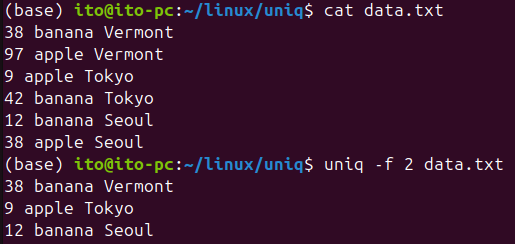
-f N (Ignore the first N fields)
The -f option ignores the first N fields when comparing lines for duplicates. This is useful when only certain parts of the data are important.
uniq -f 2 sorted.txtIn this example, the command ignores the first two fields of each line and compares the remaining fields for duplicates.
-s N (Ignore the first N characters)
The -s option ignores the first N characters of each line when checking for duplicates.
uniq -s 4 sorted.txtThis command ignores the first 4 characters of each line and compares the remaining part to determine whether lines are duplicates.
Precautions When Using the uniq Command
- Use with the sort command: As mentioned earlier, the
uniqcommand only processes consecutive duplicate lines. To handle data correctly, it is recommended to use thesortcommand along withuniq. If the data is not sorted, even if there are duplicate lines,uniqmay not detect them. - Processing speed with large files: When dealing with large files, using both
sortanduniqmay take some time. In such cases, you may want to split the file or choose options that use less memory.
Summary
The Linux command uniq is a powerful tool for filtering duplicate content when processing files or data in Linux. It is especially useful for checking and removing duplicates when analyzing or organizing data, and it offers a variety of options to filter data in the desired way. The uniq command can be used not only to remove duplicates but also to count duplicate occurrences, ignore case, or even skip certain fields or characters. However, remember that uniq only processes consecutive duplicate lines, so it is crucial to use it along with the sort command.
Use the uniq command appropriately to increase efficiency when processing data in Linux!