리눅스 명령어 awk는 텍스트 파일에서 데이터를 추출하거나 변형하는 데 특화된 도구로, 매우 강력한 기능을 제공합니다. 이번 포스팅에서는 awk의 기본적인 사용법부터 주요 옵션까지 알아보겠습니다.
목차
리눅스 명령어 awk란 무엇인가요?
awk는 텍스트 기반 데이터를 처리하는 프로그래밍 언어이자 도구입니다. 주로 행과 열로 이루어진 데이터를 처리할 때 사용됩니다. 예를 들어, 로그 파일에서 특정 열을 추출하거나, CSV 파일에서 특정 값을 계산하는 등의 작업에 많이 활용됩니다.
awk는 크게 다음과 같은 작업에 유용합니다:
- 텍스트 필드 추출: 파일의 특정 열(필드)만을 출력할 수 있습니다.
- 조건에 따른 처리: 특정 조건을 만족하는 행을 선택할 수 있습니다.
- 데이터 변환: 데이터 형식을 변환하거나 수식을 계산할 수 있습니다.
awk 기본 문법
awk는 보통 다음과 같은 형식으로 사용됩니다:
awk '패턴 {동작}' 파일명여기서 패턴은 선택적이며, 텍스트 파일에서 특정 조건을 만족하는 행을 지정하는 부분입니다. 동작은 조건을 만족하는 행에서 수행할 작업을 정의합니다. 예를 들어, 특정 열만 출력하거나, 특정 조건을 만족하는 데이터를 추출할 수 있습니다.
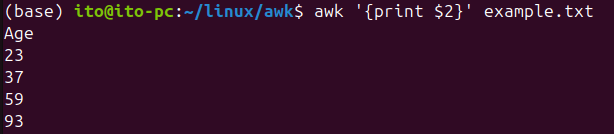
다음은 텍스트 파일에서 두 번째 열을 출력하는 awk 명령어입니다.
awk '{print $2}' 파일명여기서 $2는 두 번째 열을 의미합니다. $1은 첫 번째 열, $3은 세 번째 열을 나타냅니다. 이런 식으로 열 번호를 지정하여 출력할 수 있습니다. 기본적으로 열과 열은 공백으로 구분합니다. 다음과 같은 example.txt 파일이 있습니다.
Name Age
Freud 23
Rachel 37
Mary 59
Adler 93awk 명령어를 사용해서 두 번째 열을 추출한 결과는 다음과 같습니다.
awk의 주요 옵션
awk는 다양한 옵션과 함께 사용할 수 있습니다. 자주 사용하는 몇 가지 옵션을 소개하겠습니다.
-F 옵션: 필드 구분자 지정
기본적으로 awk는 공백을 필드 구분자로 사용합니다. 하지만 CSV 파일처럼 콤마(,)로 구분된 파일을 처리하려면, 필드 구분자를 변경해야 합니다. 이때 -F 옵션을 사용하면 됩니다.
awk -F',' '{print $1, $2}' 파일명위 명령어는 콤마(,)를 필드 구분자로 설정한 후, 첫 번째와 두 번째 필드를 출력합니다. example.csv 파일의 내용은 아래와 같습니다.
Name,Age
Freud,23
Rachel,37
Mary,59
Adler,93콤마를 구분자로 하여 첫 번째 값과 두 번째 값을 출력합니다.

패턴 사용: 특정 조건을 만족하는 행 처리
awk는 조건에 따라 특정 행만 처리할 수 있습니다. 예를 들어, 파일의 두 번째 열이 특정 값인 경우에만 해당 행을 출력하려면 다음과 같이 작성할 수 있습니다:
awk '$2 == "값"' 파일명아래는 두 번째 열이 23과 일치하는 행만 출력한 결과입니다.

BEGIN과 END 블록
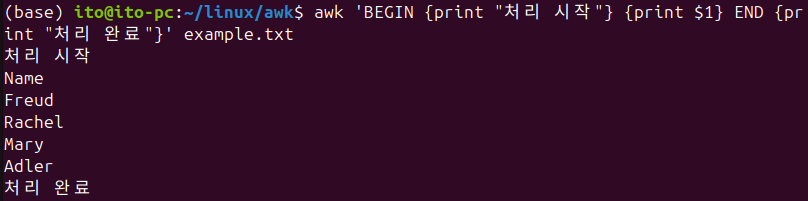
awk에는 BEGIN과 END 블록이 있습니다. BEGIN 블록은 파일을 처리하기 전에 한 번 실행되고, END 블록은 파일 처리가 끝난 후에 한 번 실행됩니다.
awk 'BEGIN {print "처리 시작"} {print $1} END {print "처리 완료"}' 파일명이 명령어는 아래와 같이 파일의 첫 번째 열을 출력하기 전에 “처리 시작”을 출력하고, 마지막에 “처리 완료”를 출력합니다.
실용적인 활용 예시
특정 패턴이 포함된 행 출력
파일에서 특정 문자열이 포함된 행만 출력하고 싶다면 다음과 같은 명령어를 사용할 수 있습니다:
awk '/패턴/' 파일명예를 들어, 로그 파일에서 에러 메시지가 포함된 행을 찾으려면:
awk '/ERROR/' /var/log/syslog이 명령어는 아래와 같이 syslog 파일에서 “ERROR”라는 문자열이 포함된 모든 행을 출력합니다.

합계 계산하기
awk는 간단한 계산도 가능합니다. 예를 들어, 파일의 두 번째 열에 있는 값들의 합계를 구하려면 다음 명령어를 사용할 수 있습니다:
awk '{sum += $2} END {print sum}' 파일명이 명령어는 파일의 두 번째 열을 모두 더한 결과를 출력합니다.

주의사항
awk를 사용할 때 주의할 점은 구분자를 정확하게 설정해야 한다는 것입니다. 구분자가 제대로 설정되지 않으면 원하는 대로 필드가 추출되지 않기 때문에, 데이터의 형식에 맞게 필드 구분자를 지정하는 것이 중요합니다. 특히 CSV 파일을 처리할 때는 -F',' 옵션을 자주 사용해야 합니다.
또한, awk는 대소문자를 구분하므로, 패턴 매칭 시 대소문자를 정확하게 입력해야 합니다. 대소문자를 구분하지 않고 매칭하려면 tolower 함수를 사용할 수 있습니다.
awk '{if (tolower($0) ~ /error/) print $0}' logfile.txt이 명령어는 아래와 같이 대소문자에 상관없이 “error”가 포함된 행을 출력합니다.

정리
awk는 리눅스에서 텍스트 파일을 처리할 때 매우 유용한 도구입니다. 기본적인 필드 추출부터 조건부 출력, 계산까지 다양한 작업을 간단한 명령어로 처리할 수 있습니다. 특히 로그 파일 분석, 데이터 전처리 등에 많이 사용되며, 강력한 텍스트 처리 능력을 갖추고 있습니다.