Linuxコマンドawkは、テキストファイルからデータを抽出または変換するために特化したツールであり、非常に強力な機能を提供します。この記事では、awkの基本的な使い方から主要なオプションまで詳しく説明します。
目次
Linuxコマンドawkとは?
awkは、テキストベースのデータを処理するためのプログラミング言語およびツールです。主に行と列からなるデータを処理する際に使用されます。例えば、ログファイルから特定の列を抽出したり、CSVファイルの特定の値を計算する際によく利用されます。
awkは次のような作業に役立ちます:
- テキストフィールドの抽出: ファイルの特定の列(フィールド)を出力できます。
- 条件に基づいた処理: 特定の条件を満たす行を選択できます。
- データの変換: データ形式の変換や数式の計算が可能です。
awkの基本文法
awkは通常、次のような形式で使用されます:
awk 'パターン {動作}' ファイル名ここでパターンは任意で、テキストファイルから特定の条件を満たす行を指定する部分です。動作は、その条件を満たす行に対して実行する作業を定義します。例えば、特定の列だけを出力したり、特定の条件に合うデータを抽出したりできます。
次に、テキストファイルの2番目の列を出力するawkコマンドを示します。
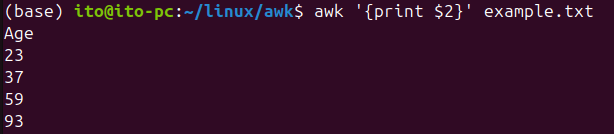
awk '{print $2}' ファイル名ここで $2 は2番目の列を意味します。$1 は1番目の列、$3 は3番目の列を指します。このようにして、列番号を指定して出力することができます。基本的に、列と列の区切りはスペースで行われます。次のような example.txt ファイルがあります。
Name Age
Freud 23
Rachel 37
Mary 59
Adler 93awkコマンドを使用して2番目の列を抽出した結果は次の通りです。
awkの主要オプション
awkは様々なオプションと一緒に使用できます。よく使用されるいくつかのオプションを紹介します。
-Fオプション: フィールド区切り文字の指定
基本的にawkはスペースをフィールドの区切り文字として使用します。しかし、CSVファイルのようにカンマ(,)で区切られたファイルを処理する場合、区切り文字を変更する必要があります。その際、-F オプションを使用します。
awk -F',' '{print $1, $2}' ファイル名このコマンドではカンマをフィールド区切り文字として設定した後、1番目と2番目のフィールドを出力します。example.csv ファイルの内容は以下の通りです。
Name,Age
Freud,23
Rachel,37
Mary,59
Adler,93カンマを区切り文字として、1番目と2番目の値を出力します。

パターン使用: 特定の条件を満たす行の処理
awkは条件に基づいて特定の行だけを処理することができます。例えば、ファイルの2番目の列が特定の値に一致する行だけを出力するには、次のように記述します。
awk '$2 == "値"' ファイル名以下は、2番目の列が 23 に一致する行だけを出力した結果です。

BEGINとENDブロック
awkには BEGIN と END ブロックがあります。BEGIN ブロックはファイルを処理する前に一度実行され、END ブロックはファイルの処理が完了した後に一度実行されます。
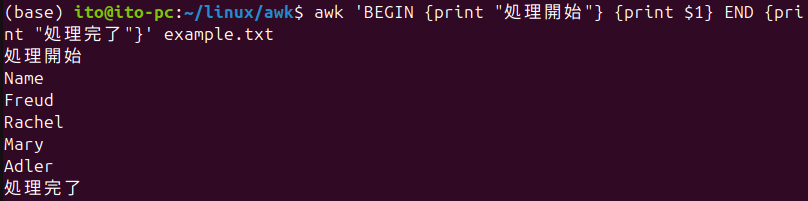
awk 'BEGIN {print "処理開始"} {print $1} END {print "処理完了"}' ファイル名このコマンドは、ファイルの1番目の列を出力する前に “処理開始” を表示し、最後に “処理完了” を表示します。
実用的な使用例
特定のパターンを含む行の出力
ファイルから特定の文字列を含む行だけを出力したい場合、次のようなコマンドを使用します。
awk '/パターン/' ファイル名例えば、ログファイルでエラーメッセージを含む行を探したい場合:
awk '/ERROR/' /var/log/syslogこのコマンドは、syslogファイルから “ERROR” という文字列を含むすべての行を出力します。

合計の計算
awkは簡単な計算も可能です。例えば、ファイルの2番目の列にある値の合計を計算するには、次のコマンドを使用します。
awk '{sum += $2} END {print sum}' ファイル名このコマンドは、ファイルの2番目の列のすべての値を合計して出力します。

注意事項
awkを使用する際に注意すべき点は、区切り文字を正確に設定することです。区切り文字が正しく設定されていないと、目的通りにフィールドを抽出できないため、データの形式に合わせて区切り文字を指定することが重要です。特にCSVファイルを処理する場合、-F',' オプションをよく使用します。
また、awkは大文字と小文字を区別するため、パターンマッチングの際には大文字と小文字を正確に入力する必要があります。大文字と小文字を区別せずにマッチングするには tolower 関数を使用できます。
awk '{if (tolower($0) ~ /error/) print $0}' logfile.txtこのコマンドは、大文字小文字に関係なく “error” が含まれる行を出力します。

まとめ
awkはLinuxでテキストファイルを処理する際に非常に便利なツールです。基本的なフィールド抽出から条件付き出力、計算まで、さまざまな作業を簡単なコマンドで処理できます。特にログファイルの解析やデータの前処理に多く使用され、強力なテキスト処理能力を備えています。