The Linux command join is useful when you need to merge two files based on a specific column, similar to the “JOIN” function in a database. In this post, we’ll explore how to use the join command and review some of its useful options.
Table of Contents
What is the Linux Command join?
The join command merges two files based on a common field. It’s commonly used when you want to merge rows from two files by matching a specific column. This function is similar to the JOIN operation frequently used in databases.
For the join command to work properly, the two files must be sorted. Thus, it is essential to use the sort command to sort the files before using join.
Basic Syntax of the join Command
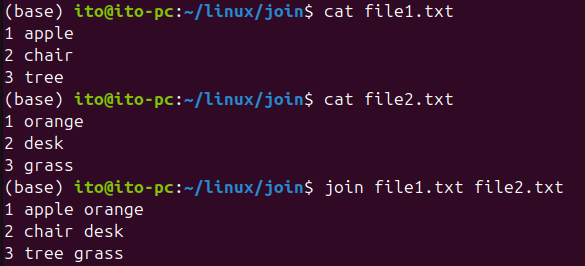
join [options] file1 file2The join command takes two files as input and merges them based on the first field by default. Here, a field refers to a column in each row of the file. When the values in the common field of both files match, the corresponding rows are merged.
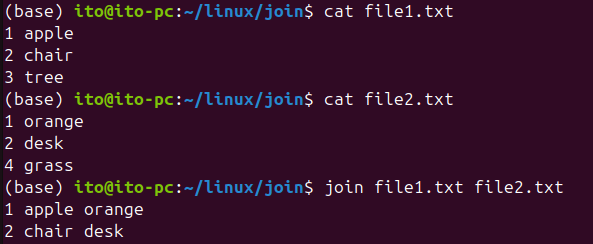
join file1.txt file2.txtAs shown below, the output merges the data based on the first field of each file, similar to how a spreadsheet might work.
Useful Options
The join command has several options that allow for more flexible merging of files. Here are some commonly used options.
-1, -2 Options: Change Key Fields
By default, the join command merges data based on the first field of both files. However, files may have different key fields. The -1 and -2 options allow you to specify which fields to use as the key for merging in each file.
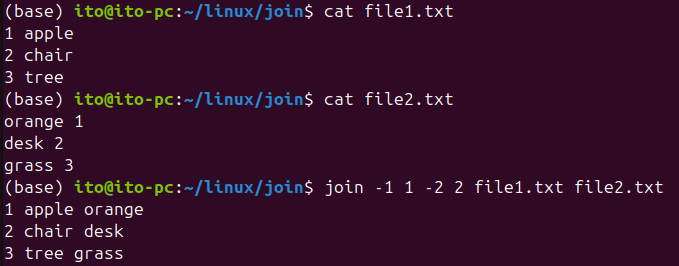
join -1 2 -2 1 file1.txt file2.txtHere, -1 2 means using the second field of the first file, and -2 1 means using the first field of the second file as the key for merging. In the following, we merge based on the first field of the first file and the second field of the second file.
-t Option: Set Delimiters
By default, the join command uses spaces as delimiters between fields. However, files may use commas or tabs as delimiters. The -t option allows you to specify the delimiter.
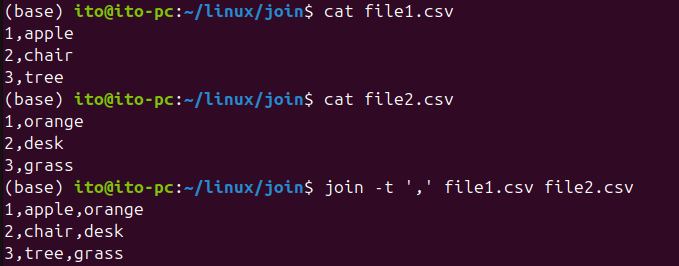
join -t ',' file1.csv file2.csvThis command works with CSV files where commas are used as delimiters. As shown below, the merged result also uses commas as delimiters.
-a Option: Display Non-matching Lines
By default, the join command only outputs rows where the key fields in both files match. Using the -a option, you can also display rows that do not have a match. The -a 1 option outputs all rows from the first file, while the -a 2 option outputs all rows from the second file.
join -a 1 file1.txt file2.txtThis command outputs all rows from the first file, and where a match is found in the second file, the merged result is displayed.
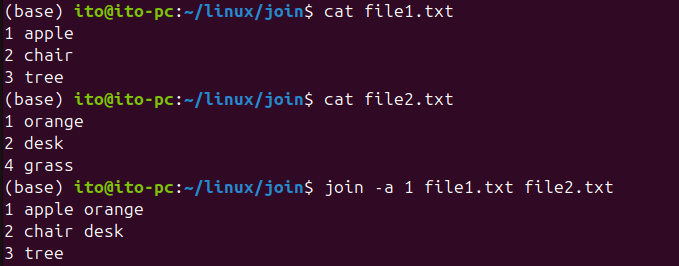
Here is the result when merging all rows from both files.

-v Option: Display Only Non-matching Lines
Conversely, if you only want to see rows that do not match between the two files, you can use the -v option. The -v 1 option outputs rows that exist only in the first file, while the -v 2 option outputs rows that exist only in the second file.
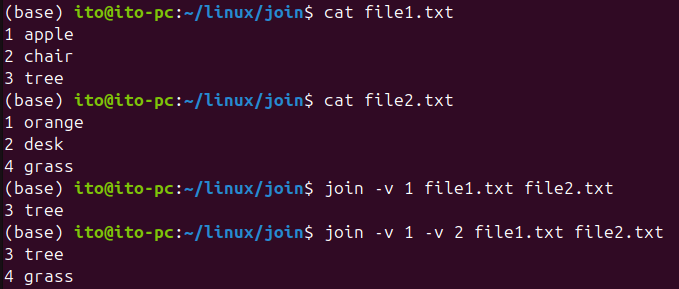
join -v 1 file1.txt file2.txtThe following shows the result when using the -v 1 option to display rows that exist only in file1.txt, and the result when using both -v 1 -v 2 to display all non-matching rows from both files.
Caution
Matching Delimiters
The join command merges rows based on matching fields, so any non-matching fields are excluded. In the following example, since the key fields “3 tree” from file1.txt and “4 grass” from file2.txt do not match, they are not output.
File Sorting
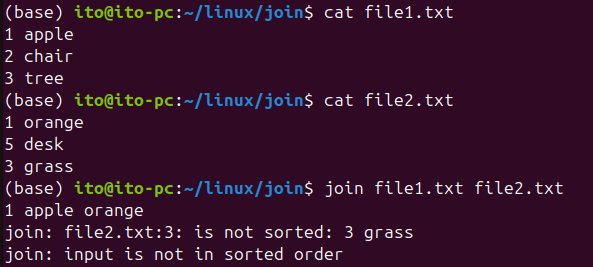
Before using the join command, it is essential to sort both files based on the key field. If the files are not sorted, you will encounter an error: “join: input is not in sorted order.” The command also specifies where the sorting issue occurred. Therefore, you must sort the files using the sort command before using join.
Consistent Delimiters
If the files use different delimiters, the join command may not work as expected. Ensure that delimiters are consistent across both files, or use the -t option to specify the delimiter.
Number of Fields
If the two files have a different number of fields, the join command may produce unexpected results. It’s important to check the number of fields in both files and preprocess the data if necessary.
Summary
The join command is a powerful tool for merging two files based on a common field in a Linux environment. It is especially useful for handling large datasets, and its various options allow for flexible data manipulation. However, before using join, ensure that the files are sorted and that delimiters are consistent.
By mastering the join command, you can easily replicate the JOIN functionality of databases within the Linux file system, making it a valuable tool for many scenarios.