리눅스 명령어 join은 두 개의 파일을 특정 컬럼을 기준으로 결합해야 할 때, 데이터베이스의 “JOIN” 기능과 유사하게 두 파일을 효과적으로 결합할 수 있습니다. 이번 포스팅에서는 join 명령어의 사용법과 유용한 옵션들에 대해 알아보겠습니다.
목차
리눅스 명령어 join이란?
join은 두 파일의 공통된 필드를 기준으로 데이터를 결합하는 명령어입니다. 주로 각 파일의 행 데이터를 특정 열을 기준으로 병합하여 출력할 때 사용됩니다. 이 명령어는 데이터베이스에서 자주 쓰이는 JOIN 연산과 비슷한 역할을 합니다.
join 명령어는 두 파일이 정렬된 상태에서만 제대로 작동하므로, 명령어를 사용하기 전에 sort 명령어를 통해 데이터를 정렬하는 것이 필수입니다.
join 명령어의 기본 문법
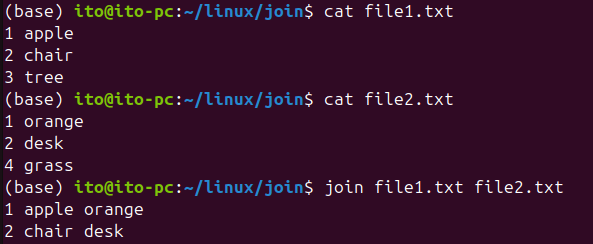
join [options] file1 file2join 명령어는 기본적으로 두 개의 파일을 입력받으며, 첫 번째 필드를 기준으로 데이터를 병합합니다. 여기서 필드란 파일의 각 행을 이루는 열을 의미합니다. 두 파일에서 공통된 필드의 값이 일치할 때 해당 행을 병합하여 출력합니다.
join file1.txt file2.txt아래 예시에서 보듯이, 마치 스프레드시트 형태와 같이 각 파일의 첫 번째 필드를 기준으로 데이터를 결합하여 하나의 출력으로 보여줍니다.
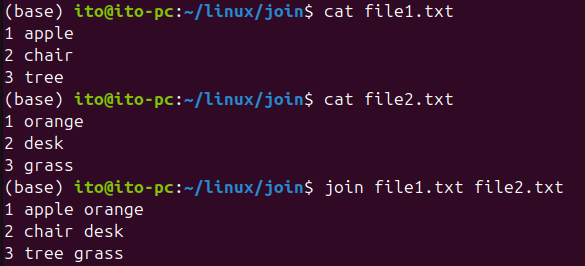
유용한 옵션들
join 명령어에는 다양한 옵션이 있어 파일 결합을 보다 유연하게 할 수 있습니다. 그 중 자주 사용하는 옵션 몇 가지를 살펴보겠습니다.
-1, -2 옵션: 기준 필드 변경
기본적으로 join은 두 파일의 첫 번째 필드를 기준으로 데이터를 결합합니다. 그러나 파일마다 기준이 되는 필드가 다를 수 있습니다. 이때 -1과 -2 옵션을 사용하면, 각 파일의 어느 필드를 기준으로 결합할지 지정할 수 있습니다.
join -1 2 -2 1 file1.txt file2.txt여기서 -1 2는 첫 번째 파일에서 두 번째 필드를, -2 1은 두 번째 파일에서 첫 번째 필드를 기준으로 결합하라는 의미입니다. 아래에서는 -1 1로 첫 번째 파일에서는 첫째 필드를, -2 2로 두 번째 파일에서는 두 번째 필드를 기준으로 병합하게 한 결과입니다.
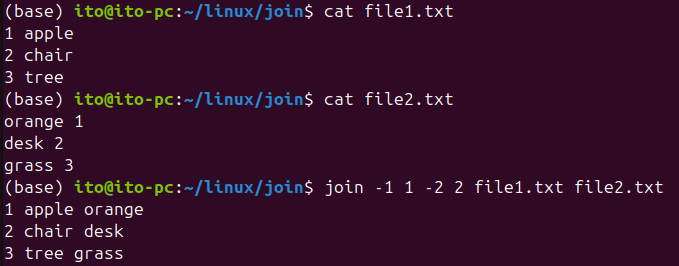
-t 옵션: 구분자 설정
기본적으로 join 명령어는 공백을 기준으로 필드를 구분합니다. 하지만 파일 내에서 콤마(,)나 탭(\t)과 같은 다른 구분자가 사용될 수 있습니다. 이때 -t 옵션을 사용하여 구분자를 지정할 수 있습니다.
join -t ',' file1.csv file2.csv위 예시는 파일이 콤마로 구분된 CSV 파일일 경우, 각 필드를 정확하게 인식하고 결합합니다. 또한 아래의 그림과 같이 결합된 결과도 콤마로 구분하여 돌려줍니다.
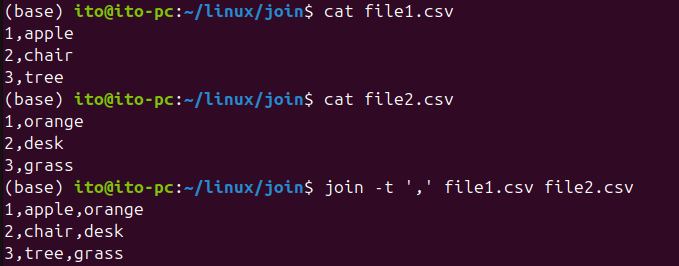
-a 옵션: 일치하지 않는 행도 출력
join 명령어는 기본적으로 두 파일에서 공통된 필드의 값이 일치하는 행만 출력합니다. 하지만 -a 옵션을 사용하면, 일치하지 않는 행도 출력할 수 있습니다. 이때 -a 1은 첫 번째 파일의 모든 행을, -a 2는 두 번째 파일의 모든 행을 출력합니다.
join -a 1 file1.txt file2.txt이 명령은 첫 번째 파일의 모든 행을 출력하고, 두 번째 파일에서 일치하는 필드가 있을 경우에만 결합된 값을 출력합니다.
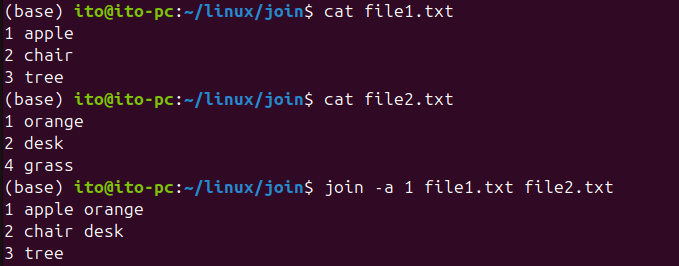
이번에는 두 파일의 모든 필드의 값을 병합하게 한 결과입니다.

-v 옵션: 일치하지 않는 행만 출력
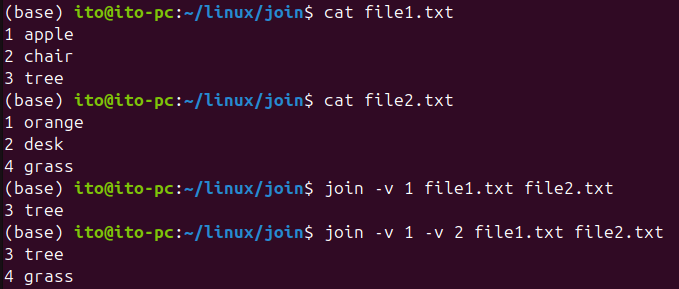
반대로, 두 파일에서 일치하지 않는 행만 보고 싶을 때는 -v 옵션을 사용합니다. -v 1은 첫 번째 파일에서만 존재하는 데이터를, -v 2는 두 번째 파일에서만 존재하는 데이터를 출력합니다. 아래의 명령은 첫 번째 파일에만 있고 두 번째 파일에는 없는 데이터를 출력합니다.
join -v 1 file1.txt file2.txt다음의 결과는 -v 1 옵션을 사용하여 file1.txt에만 있는 데이터를 출력한 결과와 -v 1 -v 2 옵션을 사용하여 file1.txt와 file2.txt에서 일치하지 않는 모든 데이터를 출력하게 한 결과입니다.
주의사항
구분자 일치
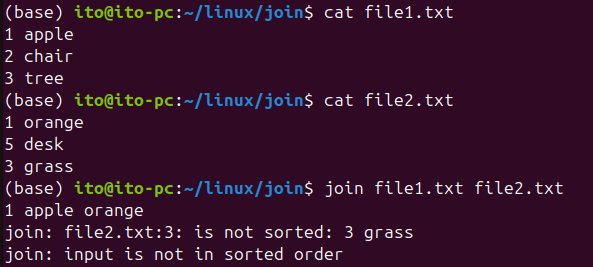
join 명령어는 기본적으로 일치하는 필드를 기준으로 병합하므로, 일치하지 않는 필드는 제외됩니다. 다음 그림은 file1.txt의 3 tree와 file2.txt의 4 grass의 기준 필드가 일치하지 않으므로 출력되지 않는 것을 볼 수 있습니다.
파일 정렬
join 명령어를 사용하기 전에 반드시 두 파일을 동일한 기준 필드로 정렬해야 합니다. 정렬되지 않은 상태에서 명령어를 실행하면 “join: input is not in sorted order”라고 오류 상황을 알려줍니다. 그리고 어떤 파일에서 어떤 부분이 정렬되지 않은 것인지도 친절하게 알려주죠. 따라서 sort 명령어를 이용해 파일을 정렬한 후 사용해야 합니다.
구분자 일관성
파일 간에 구분자가 다르면 join 명령어가 제대로 작동하지 않을 수 있습니다. 구분자를 일관되게 사용하거나 -t 옵션을 사용해 구분자를 명시하는 것이 좋습니다.
필드 개수
join 명령어는 필드 개수가 다른 파일을 결합할 때 예기치 않은 결과를 낼 수 있습니다. 두 파일의 필드 개수를 확인하고, 필요한 경우 미리 데이터를 처리해야 합니다.
정리
join 명령어는 리눅스 환경에서 두 개의 파일을 특정 필드를 기준으로 결합할 때 유용하게 사용할 수 있는 도구입니다. 특히, 대량의 데이터 처리 시 필수적인 기능 중 하나로, 다양한 옵션을 통해 보다 유연하게 데이터를 다룰 수 있습니다. 다만, 사용 전에 파일이 정렬되어 있는지, 구분자가 일관되게 설정되어 있는지 확인하는 것이 중요합니다.
join 명령어를 잘 활용하면, 데이터베이스의 JOIN 기능을 리눅스 파일 시스템에서도 간편하게 구현할 수 있어 여러 상황에서 유용하게 사용할 수 있을 것입니다.