Linuxコマンドuniqは、ファイルやデータを処理する際に、重複した内容を削除したり、重複した項目を見つけるために使用します。今回の投稿では、uniqコマンドの使い方とオプションについて説明し、それをどのように効率的に使用できるかを紹介します。
目次
uniqコマンドとは?
uniqは、Linuxでファイルやデータを扱う際に、重複した行を確認し、重複した行をフィルタリングするコマンドです。しかし、uniqは連続した重複行のみを処理するため、重複している内容が連続していない場合には期待する結果を得られません。そのため、通常はuniqコマンドを使用する前に、sortコマンドを使用してファイルをソートし、その後重複項目を削除するのが一般的です。
uniqの使い方
uniqコマンドの基本的な構文は以下の通りです:
uniq [オプション] [入力ファイル] [出力ファイル]- [オプション]: 重複項目をフィルタリングするために使用するさまざまなオプション。
- [入力ファイル]: 重複を削除するファイル。
- [出力ファイル]: フィルタリング結果を保存するファイル。
uniqコマンドは、基本的に入力ファイルの連続した重複行を削除し、出力ファイルに保存します。入力ファイルが指定されていない場合、標準入力(キーボード入力)を使用し、出力ファイルが指定されていない場合は標準出力(ターミナル画面)に結果を出力します。
次のようなファイルがあります:
apple
apple
raspberry
banana
banana
apple
raspberry
raspberry
watermelonuniqコマンドを使用すると、以下のように連続している重複した値が削除されることがわかります。
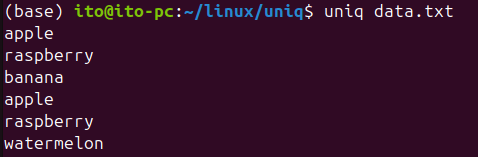
次に、sortコマンドを組み合わせてuniqコマンドを使用して、重複行を削除する例です。この場合、sortコマンドで-uオプションを使用したときと同じ結果が得られます。
sort data.txt | uniq > result.txtsort data.txt: data.txtファイルの内容をソートします。uniq: ソートされたファイルから連続した重複行を削除します。> result.txt: 結果をresult.txtファイルに保存します。
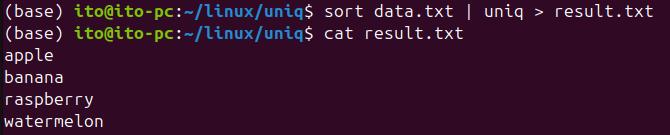
ここでsortコマンドを先に使用する理由は、uniqが連続した重複行のみを削除するためです。ソートされていないデータでは、重複行があってもuniqがそれを検出できない可能性があります。
uniqコマンドのオプション
uniqコマンドにはさまざまなオプションがあります。いくつかの重要なオプションを見てみましょう。
-c(重複行の数を表示)
-cオプションは、重複行が何回出現したか、その回数を表示します。このオプションを使用すると、重複の有無だけでなく、重複の回数も確認できます。
uniq -c sorted.txt以下のように、appleは3回、bananaは2回、raspberryは3回出現していることがわかります。

-d(重複した行のみを表示)
-dオプションは、重複している行のみを表示します。重複していない行は表示されないため、重複データを探すときに便利です。
uniq -d data.txt以下のように、重複しているapple、banana、raspberryのみが表示されることが確認できます。

-u(重複していない行のみを表示)
逆に、-uオプションは重複していない行のみを表示します。ユニークなデータを抽出したいときに使用します。
uniq -u data.txtソートされていないデータを使用すると、連続して重複していないものも表示されます。そのため、ソート後にuniqを使用することで期待通りの結果が得られることを忘れないでください。以下の結果では、重複していないwatermelonが表示されています。
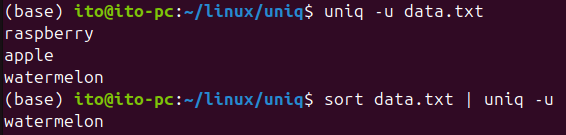
-i(大文字と小文字を無視)
-iオプションは、大文字と小文字を無視して重複を検出します。このオプションを使用すると、大文字と小文字が混在しているデータでも、より正確に重複を検出できます。つまり、Appleとappleを同じ文字列として認識します。
uniq -i sorted.txt以下のように、Appleとappleが重複として処理されていることが確認できます。
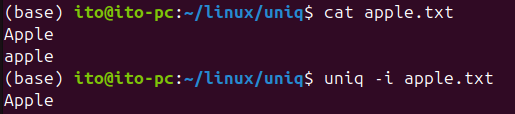
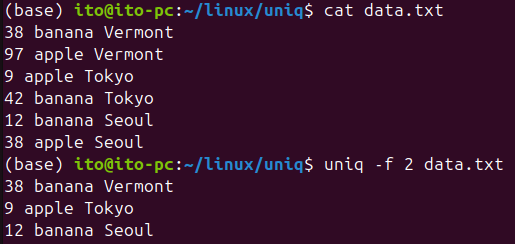
-f N(N個のフィールドを無視)
-fオプションは、最初のN個のフィールドを無視して重複を検出できます。データの一部フィールドが重要な場合に便利です。
uniq -f 2 sorted.txtこのコマンドは、以下のように各行の最初の2つのフィールドを無視して、残りのフィールドのみを比較し、重複を検出します。
-s N(N個の文字を無視)
-sオプションは、各行の最初のN文字を無視して重複を検出します。
uniq -s 4 sorted.txtこのコマンドは、各行の最初の4文字を無視し、残りの部分を比較して重複を判断します。
uniqコマンドを使用する際の注意点
- sortと併用すること: 先述のように、uniqコマンドは連続した重複行のみを処理するため、データを正確に処理するにはsortコマンドと一緒に使用することが推奨されます。データがソートされていないと、重複行があってもuniqがそれを認識できない場合があります。
- 大容量ファイルの処理速度: 大容量ファイルを処理する際、sortとuniqを併用する作業には時間がかかることがあります。その際は、ファイルを分割して処理するか、メモリを節約するオプションを選択することが有効です。
まとめ
Linuxコマンドuniqは、Linuxでファイルやデータを処理する際に、重複した内容をフィルタリングできる強力なツールです。特に、データを分析したり整理する際に、重複した項目を確認するのに役立ち、さまざまなオプションを使用して、望む方法でデータをフィルタリングできます。uniqコマンドは単純な重複削除だけでなく、重複データの数を確認したり、大文字小文字の無視、特定のフィールドや文字を無視するなど、さまざまな方法で活用できます。ただし、uniqが連続した重複行のみを処理する点を覚えておき、必ずsortコマンドと併用するのが良いでしょう。
Linuxでデータ処理の効率を高めるために、uniqコマンドを適切に使ってみてください!