리눅스 명령어 uniq는 파일이나 데이터를 처리할 때 중복된 내용을 제거하거나, 중복된 항목을 찾을 때 사용합니다. 이번 포스팅에서는 uniq 명령어의 사용법과 옵션을 알아보고, 이를 어떻게 효율적으로 사용할 수 있는지에 대해 설명하겠습니다.
목차
uniq 명령어란?
uniq는 리눅스에서 파일이나 데이터를 다룰 때 중복된 내용을 확인하고, 중복된 행을 필터링할 수 있는 명령어입니다. 하지만 uniq는 오직 연속된 중복 행만 처리하므로, 중복된 내용이 연속되지 않으면 원하는 결과를 얻을 수 없습니다. 따라서 일반적으로 uniq 명령어를 사용하기 전에는 sort 명령어를 함께 사용하여 파일을 정렬한 후 중복된 항목을 제거하는 것이 일반적입니다.
uniq 사용법
uniq 명령어의 기본 구문은 다음과 같습니다:
uniq [옵션] [입력 파일] [출력 파일][옵션]: 중복된 항목을 필터링하는 데 사용하는 다양한 옵션들.[입력 파일]: 중복을 제거할 파일.[출력 파일]: 필터링된 결과를 저장할 파일.
uniq 명령어는 기본적으로 입력 파일의 연속된 중복된 행을 제거한 후 출력 파일에 저장합니다. 입력 파일이 명시되지 않은 경우 표준 입력(키보드 입력)을 사용하고, 출력 파일이 명시되지 않은 경우 표준 출력(터미널 화면)에 결과를 출력합니다.
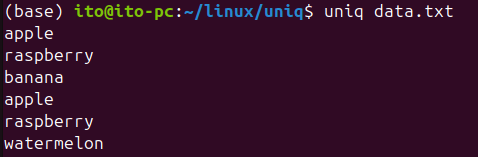
다음과 같은 파일이 있습니다.
apple
apple
raspberry
banana
banana
apple
raspberry
raspberry
watermelonuniq 명령어를 사용하면 다음과 같이 연속해서 중복된 값이 제거되는 것을 볼 수 있습니다.
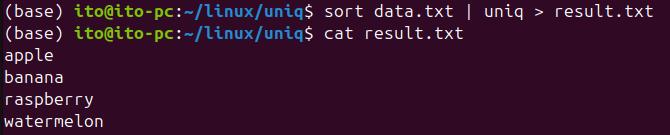
다음은 sort 명령어를 함께 사용하여 uniq 명령어를 사용하여 중복된 행을 제거하는 예시입니다. 이 경우는 sort 명령어에서 -u 옵션을 사용했을 때와 같은 결과가 나옵니다.
sort data.txt | uniq > result.txtsort data.txt:data.txt파일의 내용을 정렬합니다.uniq: 정렬된 파일에서 연속된 중복 행을 제거합니다.> result.txt: 결과를result.txt파일에 저장합니다.
여기서 sort 명령어를 먼저 사용하는 이유는 uniq가 연속된 중복 행만 제거하기 때문입니다. 정렬되지 않은 데이터에서는 중복된 행이 있어도 uniq가 이를 감지하지 못할 수 있습니다.
uniq 명령어 옵션
uniq 명령어에는 다양한 옵션이 있습니다. 몇 가지 중요한 옵션들을 살펴보겠습니다.
-c (중복된 행의 개수 출력)
-c 옵션은 중복된 행이 몇 번 등장했는지 그 개수를 함께 출력합니다. 이 옵션을 사용하면 중복 여부뿐만 아니라 중복된 횟수도 확인할 수 있습니다.
uniq -c sorted.txt다음과 같이 apple은 3번, banana는 2번, raspberry는 3번 등장했음을 알 수 있습니다.

-d (중복된 행만 출력)
-d 옵션은 중복된 행들만 출력합니다. 중복되지 않은 행은 출력하지 않으므로, 중복된 데이터를 찾을 때 유용합니다.
uniq -d data.txt아래와 같이 중복된 값 apple, banana, raspberry만 출력되는 것을 확인할 수 있습니다.

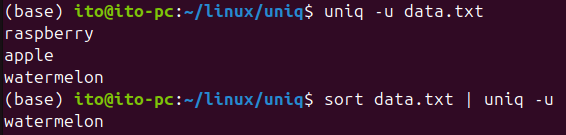
-u (중복되지 않은 행만 출력)
반대로 -u 옵션은 중복되지 않은 행들만 출력합니다. 유니크한 데이터를 걸러내고 싶을 때 사용합니다.
uniq -u data.txt정렬되지 않은 데이터를 사용하면 연속해서 중복되지 않은 것도 다음과 같이 알려주므로, 정렬 후 uniq를 사용했을 때 원하는 결과를 얻을 수 있다는 점 잊지 마세요. 다음 결과에서는 중복되지 않은 watermelon이 출력됩니다.
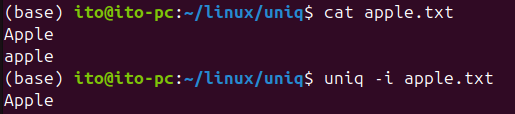
-i (대소문자 무시)
-i 옵션은 대소문자를 무시하고 중복을 검사합니다. 이 옵션을 사용하면 대소문자가 섞여 있는 데이터에서도 보다 정확한 중복 검사가 가능합니다. 즉, Apple과 apple을 동일한 문자열로 인식합니다.
uniq -i sorted.txt다음 보면 Apple과 apple을 중복된 것으로 처리하는 것을 확인할 수 있습니다.
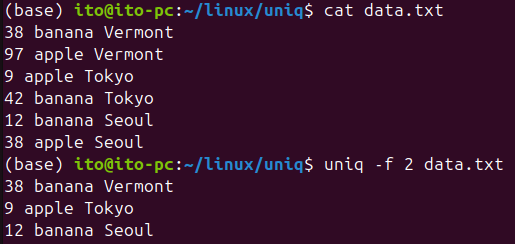
-f N (N개의 필드를 무시)
-f 옵션은 앞의 N개의 필드를 무시하고 중복을 검사할 수 있게 해 줍니다. 데이터의 일부 필드만 중요할 때 유용합니다.
uniq -f 2 sorted.txt이 명령어는 다음과 같이 각 행에서 처음 두 개의 필드를 무시하고 나머지 필드만 비교하여 중복을 검사합니다.
-s N (N개의 문자를 무시)
-s 옵션은 각 행의 처음 N개의 문자를 무시하고 중복을 검사합니다.
uniq -s 4 sorted.txt이 명령어는 각 행에서 처음 4개의 문자를 무시하고 나머지 부분을 비교하여 중복 여부를 판단합니다.
uniq 명령어 사용 시 주의사항
- sort와 함께 사용하기: 앞서 언급했듯이
uniq명령어는 연속된 중복 행만 처리하기 때문에, 데이터를 제대로 처리하기 위해서는sort명령어와 함께 사용하는 것이 좋습니다. 데이터가 정렬되어 있지 않으면 중복된 행이 있어도uniq가 이를 인식하지 못할 수 있습니다. - 파일의 큰 경우 처리 속도: 대용량 파일을 처리할 때는
sort와uniq를 함께 사용하는 작업이 시간이 걸릴 수 있습니다. 이럴 때는 파일을 나누어 처리하거나 메모리를 적게 사용하는 옵션을 선택하는 것이 유리합니다.
정리
리눅스 명령어 uniq는 리눅스에서 파일이나 데이터를 처리할 때 중복된 내용을 필터링할 수 있는 강력한 도구입니다. 특히, 데이터를 분석하거나 정리할 때 중복된 항목을 확인하는 데 유용하며, 다양한 옵션을 통해 원하는 방식으로 데이터를 필터링할 수 있습니다. uniq 명령어는 단순한 중복 제거뿐만 아니라 중복된 데이터의 개수를 확인하거나, 대소문자 무시, 특정 필드나 문자를 무시하는 등 다양한 방법으로 활용될 수 있습니다. 하지만 uniq가 연속된 중복 행만 처리한다는 점을 기억하고, 반드시 sort 명령어와 함께 사용하는 것이 좋습니다.
리눅스에서 데이터 처리의 효율성을 높이기 위해 uniq 명령어를 적절히 사용해 보세요!