The Linux command awk is a specialized tool for extracting or transforming data from text files and provides very powerful features. In this post, we will cover the basic usage of awk and explore key options that you can use with it.
Table of Contents
What is the Linux Command awk?
awk is both a programming language and a tool designed to process text-based data, often used for handling data organized in rows and columns. For example, you can use it to extract specific columns from log files or calculate specific values in CSV files.
awk is especially useful for the following tasks:
- Extracting text fields: You can output only specific columns (fields) from a file.
- Conditional processing: You can select rows that meet certain conditions.
- Data transformation: You can change the format of the data or perform calculations on it.
Basic awk Syntax
awk is typically used in the following format:
awk 'pattern {action}' filenameHere, the pattern is optional and specifies the rows in the text file that meet certain conditions. The action defines what to do with the rows that meet the condition. For example, you can output only specific columns or extract data that meets a condition.
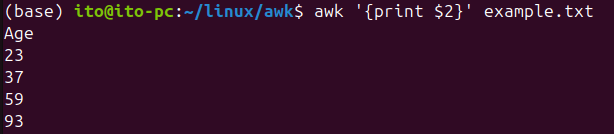
Below is an example that outputs the second column from a text file:
awk '{print $2}' filenameIn this case, $2 refers to the second column. $1 refers to the first column, and $3 refers to the third column. You can specify column numbers in this way to output specific fields. By default, columns are separated by spaces. Consider the following example.txt file:
Name Age
Freud 23
Rachel 37
Mary 59
Adler 93When you use the awk command to extract the second column, the result is as follows:
Key Options of awk
awk can be used with a variety of options. Here are a few commonly used ones.
-F Option: Specifying Field Separators
By default, awk uses spaces as the field separator. However, if you are dealing with a CSV file, where fields are separated by commas, you need to change the field separator. You can do this with the -F option.
awk -F',' '{print $1, $2}' filenameThe above command sets the comma (,) as the field separator and then outputs the first and second fields. Here’s the content of example.csv:
Name,Age
Freud,23
Rachel,37
Mary,59
Adler,93The command outputs the first and second values, using the comma as the separator.

Using Patterns: Processing Rows That Meet Certain Conditions
You can use awk to process only the rows that meet certain conditions. For instance, to print rows where the second column matches a specific value, you can write:
awk '$2 == "value"' filenameBelow is the result when the second column matches the value “23”:

BEGIN and END Blocks
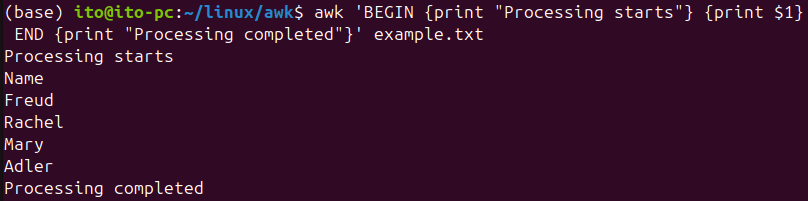
awk has BEGIN and END blocks. The BEGIN block is executed once before processing the file, and the END block is executed once after the file has been processed.
awk 'BEGIN {print "Processing starts"} {print $1} END {print "Processing completed"}' filenameThis command outputs the first column, preceded by “Processing starts” and followed by “Processing completed.”
Practical Usage Examples
Output Rows Containing a Specific Pattern
To output only the rows containing a specific string in the file, use the following command:
awk '/pattern/' filenameFor example, to find rows in a log file that contain error messages, you can use:
awk '/ERROR/' /var/log/syslogThis command outputs all rows in the syslog file that contain the string “ERROR.”

Calculating Totals
awk can also perform simple calculations. For instance, to sum up the values in the second column of a file, use the following command:
awk '{sum += $2} END {print sum}' filenameThis command outputs the total sum of the second column’s values.

Notes
When using awk, it is important to correctly set the field separator. If the separator is not properly set, the fields may not be extracted as expected. Therefore, make sure to specify the appropriate field separator for your data format, especially when handling CSV files with the -F',' option.
Additionally, awk is case-sensitive, so be sure to input patterns with the correct case. If you want to perform case-insensitive matching, you can use the tolower function.
awk '{if (tolower($0) ~ /error/) print $0}' logfile.txtThis command outputs rows that contain “error” in any case (uppercase or lowercase).

Summary
awk is a highly useful tool in Linux for processing text files. From basic field extraction to conditional output and calculations, it allows you to handle various tasks with simple commands. awk is especially powerful in log file analysis and data preprocessing, thanks to its strong text processing capabilities.